前言小记#
筆者近半年由於失戀導致更新欲低下,後來又跟隨課題組研究了圖像識別與算法分析、自動駕駛路徑規劃、智能汽車控制算法,導致更新停滯。歸功於 Computer Science 院長的栽培以及近期熱門方向的討論,要求我做一期 大模型 相關的技術分享,我才想起來更新博客。
本期博客,我將圍繞三個話題展開:
- 從雲算力到端側算力。
- AI 時代的數據隱私。
- AI 時代的算力需求
內容包含了最新的 QwQ、大語言模型訓練方法、EXO 基於網絡的算力共享、全球算力統計
從雲算力到端側算力#
讓我們使用 Apple 公司的產品 Apple Intelligence 引入這個話題
2024 年 6 月 在世界開發者大會上 Apple 公司宣布:
個人智能化系統 Apple Intelligence 為 iPhone、iPad 和 Mac 引入強大的生成式模型
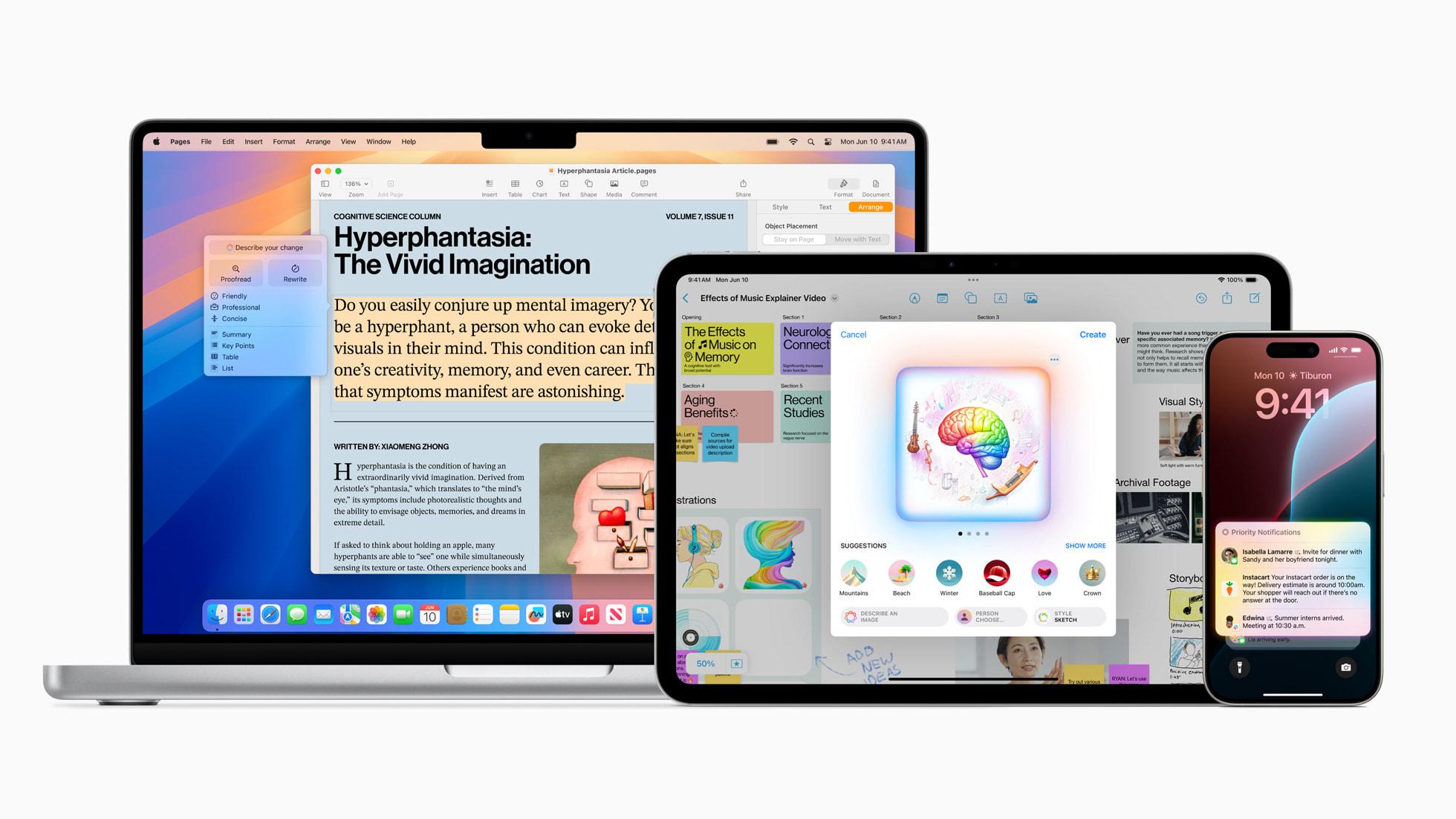
語音助手作為最典型的自然語言大模型應用場景,在 ChatGPT 爆火以後,華為、小米 以及很多公司都紛紛開始訓練和發布自己公司基於大語言模型的語音助手,而 Apple 公司則是宣布接入 GPT,但由於大陸地區的政策原因,Apple 的 AI 功能時至今日都無法在大陸地區正常使用。

直到今年 2 月份
Apple 公司將為中國地區的 iPhone 等設備集成 阿里巴巴的大語言模型 以及 其它人工智能服務 Apple 宣布接入 Alibaba 的 AI 大模型用於國行 Apple 產品。
CNBC
想必當時的大家一定是一頭霧水,當時正是 Deepseek 爆火的時候,為什麼 Apple 不選擇接入 Deepseek 這個開源大模型,而是選擇了阿里的 Qwen 系列?在 Apple 做出這個決定的時候,甚至股票一度暴跌。NVIDIA 就是因為 Deepseek 導致了自己公司的股價暴跌的呀,為什麼 Apple 會做出這個決定?

回答這個問題之前,先把目光放到 Deepseek 上。它性能十分強大,他的優點是開源,而且輕量,比起其它閉源模型來說,僅僅 671B 參數就足以與世界上最先進的模型不分伯仲。但是部署它需要多少顯存呢?

整整 700G!如果我們想部署一個輸出速度正常的 Deepseek R1 617B 版,我們可能需要大概 700G 的顯存,大概 10 張 A100 顯卡,成本可能需要 200 萬。
雖然說它相較於當初 GPT3.5、GPT4.0 所需要的算力已經大大減少了,因為那個時候 GPT 還只能在雲端使用,它所依賴的是 OpenAI 公司背後所擁有的龐大算力集群,這對於一般的企業可以說是望塵莫及的。但是好在 OpenAI 的產品推動了這方面的革命,讓 Deepseek 得以誕生,也歸功於 Deepseek 的開源,讓更多的新模型足以站在偉人之肩,這時候 QwQ 誕生了!

2025 年 3 月 6 日,阿里的千問團隊 重磅發布 QwQ 開源大模型,參數量僅 32B!

強大的 QwQ 以 32B 的少量參數(在大模型裡算是)就足以媲美 Deepseek R1 671B 滿血版,甚至超越了 Deepseek!QwQ 回應了 Apple 選擇阿里的原因,對於個人用戶只需要一張 4090 顯卡就可以運行,成本從 200 萬一步壓縮到了 2 萬。可事實是這樣嗎?近期媒體都在吹捧,可事實是……?
阿里團隊是這樣描述 QwQ 的:
這是一款擁有 320 億參數的模型,其性能可與具備 6710 億參數(其中 370 億被激活)的 DeepSeek-R1 媲美
《QwQ-32B: 領略強化學習之力》
沒錯 QwQ 僅僅與 激活了 370B Deepseek 做了性能比較…………………… 嗎?
架構#
我在技術研討會中並未提及的事情就是, QwQ 僅僅與激活了 370B Deepseek 做了性能比較,但這正是我要講的一大重大部分,Deepseek 以及基於其方式的 QwQ 模型的架構問題。(因為分享會邀請了兩個非專業的老師和群眾旁聽,並且向我們提問,因此我必須講的簡單易懂,分享會時減去了很多細節內容)
歸功於 Dense 架構,消費級計算設備就足以運行 QwQ,而 Deepseek 則是 MoE 架構,或者說 Hybrid MoE 混合專家架構,基於結果來看似乎 Dense 架構會好一點?實則不然,需要從架構細節講起。
這兩種架構有何區別?
Mixture of Experts(MoE)模型是一種通過將模型分成多個專家子網絡,並根據輸入數據的特點,動態選擇合適的專家進行計算的架構。每個 “專家” 都在某個領域擁有強大的處理能力,而 MoE 則根據任務需求智能選擇合適的專家進行運算。這一機制在保證較小計算開銷的同時,能夠顯著提升模型的表達能力和靈活性。尤其在面對大規模數據集時,MoE 模型通過精確地選擇不同的專家來處理特定的任務,從而避免了冗餘計算,並有效地降低了資源消耗。
大段長描述看著很費勁,簡單的說,就是 MoE 架構設計,就是使得 AI 功能特異化,一定類型的事情,交由指定的 “專家” 模塊處理,這也是 Deepseek 在推理只激活了大約 370B 的原因。

相對於 MoE 模型,Dense 模型則是傳統的深度神經網絡架構。Dense 模型的設計理念非常簡單 —— 每個神經元(或計算單元)都參與到每個計算中。無論任務的難易程度,Dense 模型的每個參數都會參與到每次的計算中。這使得 Dense 模型在處理相對較簡單的任務時能夠表現得較為穩定,但在面對複雜問題時,Dense 模型卻顯得有些力不從心。
因為 Dense 模型沒有像 MoE 那樣智能選擇合適的計算單元,所以每次訓練時,都需要對所有參數進行計算和更新,這帶來了巨大的計算量和存儲需求。因此,Dense 模型的計算成本較高,尤其是在處理大規模數據集或複雜任務時,效率會大大降低。
簡單的說,Dense 架構就是所有參數一擁而上,力大磚飛

前面說從結果上來看 Dense 架構更勝一籌,但從架構上來看分明是 MoE 架構更勝一籌才對,可是為什麼 QwQ 使用 Dense 架構卻超越了 MoE 架構的 Deepseek?
從性能需求講起,MoE 架構得益於分任務於各個專家模型使其獲得了強大的計算推理能力,但!!!!它對硬件的要求極高,它需要十分強大的並行計算能力。而 Dense 架構則恰恰相反,即使是 CPU + 記憶體的運行模式,都不會使它的運行效率變得奇低。
MoE 就相當於嬌生慣養的超級學神,而 Dense 則恰恰是超級好養活的萌娃。
綜合來說,小參數模型採用 Dense 架構,可以提高質量,而大參數模型採用 MoE 則可以提升效率。

除開 小體量參數 彌補了 QwQ 在 Dense 架構上的不足,更重要的是他的訓練方式。
技術詳解#
QwQ 發布頁的標題是這樣寫的:領略強化學習之力

Qwen 團隊解釋到:近期的研究表明,強化學習可以顯著提高模型的推理能力。例如,DeepSeek R1 通過整合冷啟動數據和多階段訓練,實現了最先進的性能,使其能夠進行深度思考和複雜推理。
介於 QwQ 的技術報告至今依舊很少,但是它基於 Deepseek 的模式進行了訓練,因此我們可以結合部分 Deepseek 的訓練方式來解讀為何 QwQ 擁有如此強大的性能。
QwQ-32B 的訓練過程分為三個階段:預訓練、監督微調和強化學習,其中強化學習又分為兩個關鍵階段,讓 QwQ 實現了超越 Deepseek 的性能。
要解讀原因,讓我們來逐步解讀什麼是 “冷啟動”?何為強化學習?有哪兩個關鍵階段?
“冷啟動”
為了幫助大家更好的理解冷啟動,讓我舉一個日常生活的例子。
大數據推薦算法
推薦算法會根據每個用戶的喜好推薦視頻、商品等
但首次註冊的新賬號是不具備先前累積數據的,系統就無法進行精確推薦
這就是 “冷啟動”
大模型在冷啟動時,會像一個 “什麼都不會的孩子”,不斷犯錯,生成一堆毫無邏輯的答案,甚至可能陷入無意義的循環。
使用 “冷啟動數據”,在 AI 訓練的早期階段,先用小批高質量的推理數據微調模型,相當於給 AI 提供一份 “入門指南”。
參考 Deepseek 優化冷啟動步驟:
- 從大型模型生成數據 – 研究人員使用少樣本提示。
- 從 Deepseek R1 Zero 生成數據 – 由於 R1-Zero 具備一定的推理能力,研究人員從中挑選出可讀性較好的推理結果,並重新整理後作為冷啟動數據。
- 人工篩選和優化 – 人工審查部分數據,優化表達方式,使推理過程更加直觀、清晰。
最終,DeepSeek-R1 使用了數千條冷啟動數據來進行初步微調,然後再進行強化學習訓練。
強化學習#
其他機器學習方法主要是 監督學習 和 無監督學習,而強化學習是除了監督學習和無監督學習之外的第三種機器學習範式

強化學習的特點總結為以下四點:
- 沒有監督者,只有一個獎勵信號
- 反饋是延遲的而非即時
- 具有時間序列性質
- 智能體的行為會影響後續的數據
四個基本要素
強化學習系統一般包括四個要素:策略(policy),獎勵(reward),價值(value)以及環境或者說是模型(model)。接下來我們對這四個要素分別進行介紹。
策略(Policy)
策略定義了智能體對於給定狀態所做出的行為,換句話說,就是一個從狀態到行為的映射,事實上狀態包括了環境狀態和智能體狀態。我們將策略的特點總結為以下三點:
- 策略定義智能體的行為
- 它是從狀態到行為的映射
- 策略本身可以是具體的映射也可以是隨機的分佈
獎勵(Reward)
獎勵信號定義了強化學習問題的目標,在每個時間步驟內,環境向強化學習發出的標量值即為獎勵。我們將獎勵的特點總結為以下三點:
- 獎勵是一個標量的反饋信號
- 它能表徵在某一步智能體的表現如何
- 智能體的任務就是使得一個時段內積累的總獎勵值最大
價值(Value)
價值,或者說價值函數,這是強化學習中非常重要的概念,與獎勵的即時性不同,價值函數是對長期收益的衡量。我們常常會說 “既要腳踏實地,也要仰望星空”,對價值函數的評估就是 “仰望星空”,從一個長期的角度來評判當前行為的收益,而不僅僅盯著眼前的獎勵。我們將價值函數的特點總結為以下三點:
- 價值函數是對未來獎勵的預測
- 它可以評估狀態的好壞
- 價值函數的計算需要對狀態之間的轉移進行分析
環境(模型)
外界環境,也就是模型(Model),它是對環境的模擬,當給出了狀態與行為後,有了模型我們就可以預測接下來的狀態和對應的獎勵。我們將模型的特點總結為以下兩點:
- 模型可以預測環境下一步的表現
- 表現具體可由預測的狀態和獎勵來反映
強化學習架構

兩大關鍵階段#
強化學習第一階段
聚焦於數學和編程能力的提升。從冷啟動檢查點開始,基於結果的獎勵驅動的強化學習擴展方法。
數學問題訓練,模型使用專門的準確性驗證器,而非傳統獎勵模型
編程任務訓練,用代碼執行伺服器評估代碼是否通過預定義測試用例
強化學習第二階段
側重通用能力增強
模型引入通用獎勵模型和規則驗證器進行訓練。
即使是少量的訓練步驟,也顯著提升了指令跟隨、人類偏好對齊和智能體性能,並且實現通用能力提升的同時,不顯著降低第一階段獲得的數學和編程能力
依靠這些技術 使得 QwQ 模型足以四兩撥千斤,與 MoE 大參數模型不分伯仲也使得算力從雲端來到了端側(本地)但是為什麼致力於將雲計算模式放回端側,追求低算力需求的高效模型,開展本地計算模式呢?
AI 時代的數據隱私#
我們每人每天都會在互聯網上留下大量數據
這些數據又有絕大多數涉及隱私性問題
在 AI 時代如何保護個人隱私數據也成了一大難點

Apple 公司從很早以前就開始注重用戶的數據隱私
他們著重保護的就是用戶的數據隱私,甚至華為的專家寫了上萬字解析 Apple 公司的數據隱私保護策略
個人用戶不可能在本地擁有龐大的算力集群,目前個人用戶使用大模型功能的唯一途徑就是鏈接雲端,這對於數據隱私來說,是一個十分嚴峻的挑戰

比如之前就有地區禁止 Tesla 汽車,擔心道路數據交由境外處理,這是一系列敏感問題,我們十分擔心這些 使用 AI 的數據被傳輸到非法目的、有損國家利益的反面去,所以對於數據安全的保護,至關重要
端側運行大模型,可以降低成本、提升隱私數據保護性,因此需要模型有更高的效率
如果模型足夠高效,就可以同等算力下,在端側做到更多、更加高精度的事情
未來 AI 的發展方向之一應當像 QwQ 一樣,更高的效率、更低的端側算力需求
AI 時代的算力需求#
得益於 AI 技術的發展,我們已經可以使 AI 模型運行在本地,並且使用 CPU + 記憶體的模式進行計算,開源項目 EXO 通過網絡的方式,將 AI 模型的多個層分散到不同的設備上運行,以此共享算力,使得 AI 運行成本再次降低。

但這僅僅是可供運行,無法做到高效運行 以及 AI 訓練,要做到這些 我們依舊需要極高的算力。
之前提到過所有的大模型及其訓練方式,均無法脫離 “算力” 的支持,無論是強大的 Deepseek 還是高效的 QwQ 都無法擺脫算力的支持不,管是 700G 的顯存需求,還是消費級 4090 顯卡甚至是使用 CPU 計算 都是依賴的算力資源

全球電力需求數據對比#
| 年份 | 全球電力需求 | 主要變化與趨勢 |
|---|---|---|
| 2019 | 約 25,000 TWh | 中國電力需求增速預計為 5%,全社會用電量約為 7.28 萬億 - 7.41 萬億千瓦時 |
| 2024 | 約 30,000 TWh | 主要受數據中心和 AI 訓練需求驅動。谷歌和微軟的數據中心電力消耗均達到 24 TWh,比 2019 年翻一番 |
全球 AI 算力需求數據對比#
| 年份 | 全球 AI 算力 | 主要變化與趨勢 |
|---|---|---|
| 2019 | 約 10¹⁸ FLOP/s | AI 算力主要由傳統 GPU 和 TPU 提供,算力增長相對平穩,尚未進入爆發期 |
| 2024 | 約 10²¹ FLOP/s | AI 算力顯著提升,全球機器學習硬件性能以每年 43% 的速度增長,頂級硬件能效每 1.9 年翻一番,谷歌擁有超 100 萬 H100 等效算力,全球 NVIDIA 支持的計算能力平均每 10 個月翻一番 |
各大公司 2025 年預計投入資金#
| 公司 | AI 算力 (等效 H100) | 經費支出 | 主要變化與趨勢 |
|---|---|---|---|
| 谷歌 | 超 100 萬 | 750 億美元(約 5400 億元) | 用於 AI 基礎設施 |
| 微軟 | 75 萬 - 90 萬 | 800 億美元(約 5760 億元) | 用於 AI 數據中心建設,主要用於訓練 AI 模型和部署 AI 應用 |
| 阿里 | 23 萬(英偉達 GPU) | 1500 億元 | 主要用於 AI 和雲計算基礎設施建設 |
| 騰訊 | 23 萬(英偉達 GPU) | 820 億元 | 用於智算中心,主要用於顯卡伺服器和網絡建設 |
不難看出,隨著 AI 的井噴式發展,全球對算力的需求達到了前所未有的高度,同時電力需求也愈發增大,各大廠商也在加緊占領 算力 高地,算力對 AI 時代的重要性可見一斑。
與此同時,甚至出現了 “算力 = 國力” 的論調!


此文由 Mix Space 同步更新至 xLog 原始鏈接為 https://fmcf.cc/posts/technology/AIComputingPower